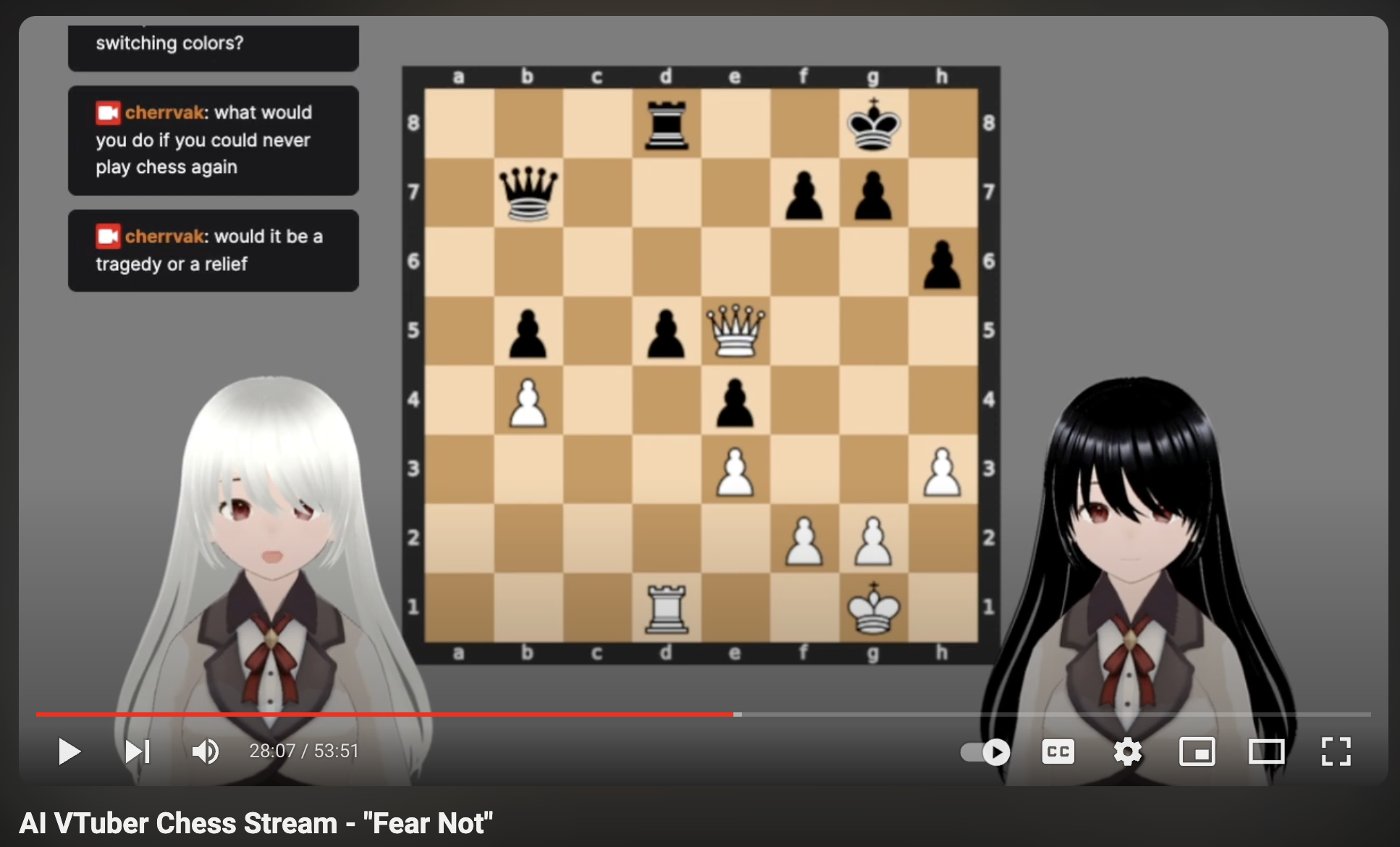
VTuber (Virtual YouTuber) is a catch-all term for an online entertainer who uses a digital avatar. A year ago, I built a fully automated setup in which two AI VTubers would play chess against each other, comment on the game and respond to Twitch stream comments:
I have automated the game of chess, for your amusement.https://t.co/mzHSZg1EQI pic.twitter.com/hw3cZVRg7r
— K Sadov (@cherrvak) July 7, 2023
I streamed a few times and then gave up on the project. This blog post is about how I built it, and why I gave up.
Neuro-sama
In 2018, a programmer started streaming videos of a neural network playing the rhythm game osu!. In 2022, he added a digital avatar of an anime girl that would converse with stream viewers while the neural network played the game in the background.
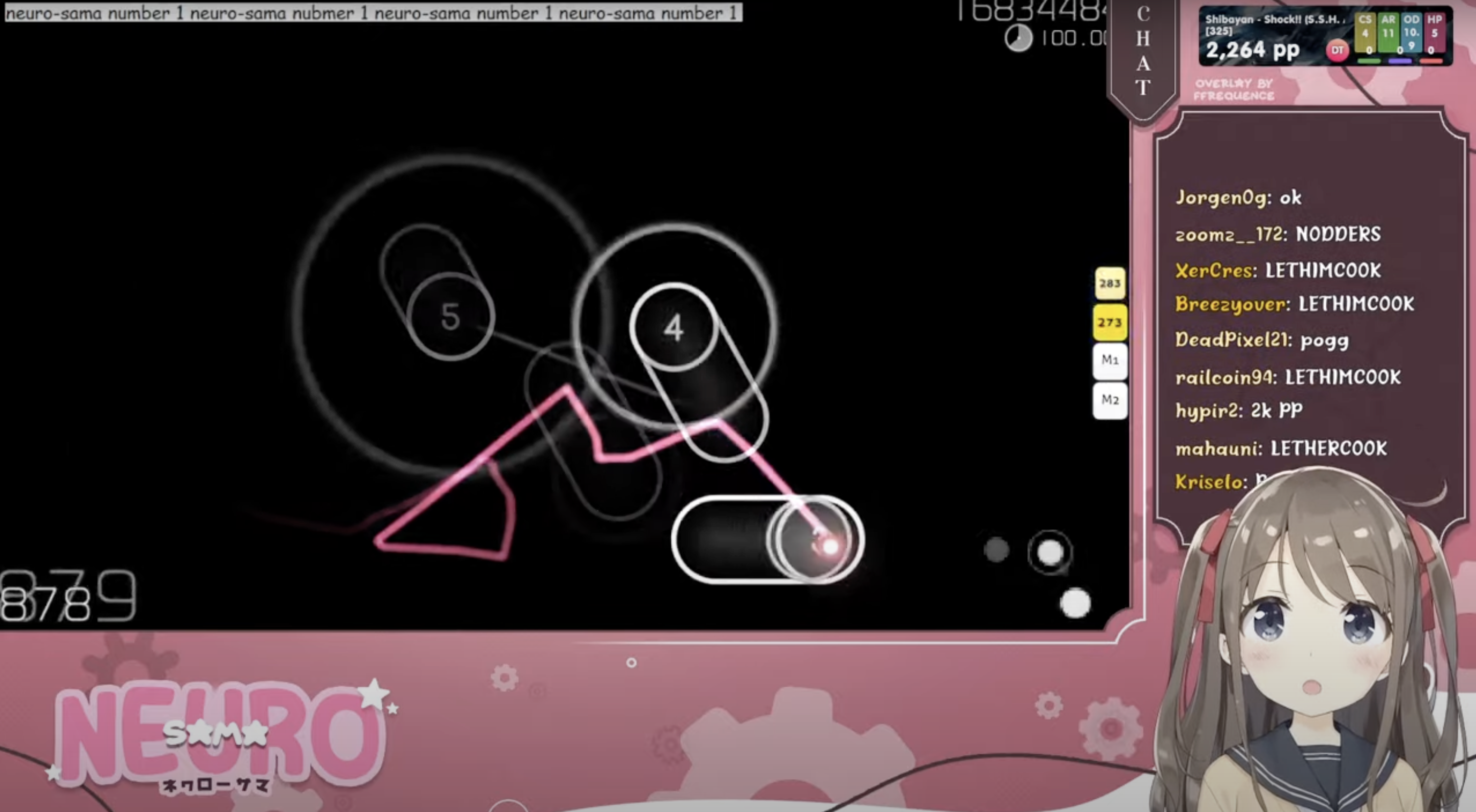
The technical stack appears to be stitched together from calls to several different interfaces: an LLM to provide dialogue, a text-to-speech service to generate audio, and now a speech-to-text service to allow the system to interact with other (human) VTubers during collaboration streams. But the modularity of the setup allowed Neuro-sama’s creator to easily bridge from osu! streams to other formats, including aforementioned collaborations and streams of the creator working on coding projects (which from Neuro-sama’s perspective must be something like being permitted a glance over the shoulder of the Demiurge).
As you can tell from that last parenthetical, it’s easy to view Neuro-sama not as a collection of ML scripts, but as an entertaining individual in her own right. Despite inconsistencies in the character’s statements (she will sometimes claim not to be an AI, or hallucinate events that couldn’t possibly have happened to her, like getting hit by a truck), Neuro-sama’s Twitch channel has over 500,000 subscribers whose fan-lore fills in for gaps produced by technical limits.
What I wanted to improve on
Neuro-sama was blind to her osu! streams. The LLM initially used to generate her chatter couldn’t take videos or still images as input, and even current multimodal models would probably struggle to interpret what’s going on in a rhythm game. It’d be cooler if she could actually comment on the games as she she was playing them.
Neuro-sama didn’t have much of an individual personality, apart from “cute”. Even her avatar was initially just a default avatar that came with the VTuber streaming software that the developer chose.
Neuro-sama didn’t have persistent memory. Unlike a real streamer, she couldn’t remember her regular viewers or even details about her self that she’d previously stated, like her favorite food (ignore the fact that Neuro-sama can’t eat, either).
How many of these points could I tackle given just a Macbook and access to various AI APIs?
Chess
The ideal game for an AI VTuber to play is be one that can easily be represented in a format parseable to the dialogue-generating LLM model: ideally, text. The LLM’s training corpus should contain many instances of commentary on the game, so that it has something to go off of when generating topical comments. It should also be something with enough broad appeal to draw many viewers.
Chess has multiple text-serializable formats, most commonly Standard Algebraic Notation. Chess game commentary can be found all over the internet, which means it’s present in the training set of any major LLM. Plus it’s more popular than even osu!.
LLMs are not particularly good at playing chess: watch for the teleporting bishops and black queen resurrection. Luckily, getting computers to play chess is a solved problem. Just like Neuro-sama’s setup has a separate osu! module, I could use a separate chess program to play moves, then send the resulting board states to an LLM for commentary.
Your standard chessbot uses calculations quite unlike that of the typical human chess player, but this can be addressed with special-purpose AI trained on human chess games. After spending a few hours trying to figure out how to integrate Maia Chess with this Python chess library, I decided to instead use the far better-behaved Stockfish bindings for the backend. From there I built a simple program that would initialize a chessboard, ask Stockfish for a move, update the board state, represent the board in SAN, send ChatGPT a request for commentary, ask Stockfish for another move, and so on until the termination of the game.
Characters
Chess is a two-player game, so why not have two AI VTubers play against each other? When chat is slow, the VTubers could fill airtime by bantering with each other. The antagonistic symbolism inherent to chess makes it possible to define the character’s personalities in contrast to each other, plus provide some extra engagement as each viewer picks their “favorite girl” to champion.
Of course, the AI VTubers would have to be girls. This wasn’t even a question. Everyone likes cute girls!
A stoic, thoughtful girl to play White, and a playful dark-haired twin to oppose her. They know that they’re AIs, and that their purpose is to entertain the viewer with chess games. A bleak existence– are viewers going to be down with that? Wouldn’t they prefer a more cheerful spin on the endeavor? Browsing Twitch streams to get a sense of the landscape, I concluded that “bleak” was, if anything, a point worth advertising.
I still felt kind of weird about simulating entities whose entire existence was suffering, so I decided that they should at least be masochistically excited about the endeavor.
I settled on the following prompt:
You are generating dialogue for a streamed chess game between Shiro and Kuro, twin AI VTuber chess players. They are irony-poisoned existential masochists. They exist in a gray void where their only purpose is to stream themselves playing chess games, a fact which both delights and horrifies them.
Shiro plays White. She is anxious and modest. She is generally reserved, but sometimes enjoys teasing her sister Kuro.
Kuro plays Black. She is mischievous and confident. She is easily flustered by her sister’s teasing.
Generate one sentence of dialog for the requested speaker.
Succinct, in order not to overwhelm my chosen LLM with detail. “Irony-poisoned”, to indicate that instead of typical tame RLHF babble, I want comments with (internet-rotted) teeth. Something topical and polemic, to keep our suffering-addicted Zoomer audience hooked.
But not too polemic, because Neuro-sama did get banned from Twitch for a bit for Holocaust denial. I stuck with ChatGPT as my LLM backend despite its annoying RLHF personality because I trusted its safety-tuning to avoid topics that would violate Twitch’s TOS.
Once I had characters down, I generated a number of visual assets with Holara to use for promotional imagery and general vibe-encapsulation. The images that you’ll see throughout the rest of this article all come from this tool. If I wanted to really nail the presentation, I would have spent some time manually painting over small errors– but I had an entire rest of the pipeline to build out!

Voice
A major part of VTubers’ appeal lies in the cuteness of their voices. Female VTubers tend to use high-pitched, expressive voices to match their neotenous, cartoony avatars, but most TTS services offer only standard adult human voices.
I initially tried ElevenLabs and was impressed by their expressivity, then ran out of free credits halfway through testing. The pricing was too steep for my use-case, so I started looking into more budget-friendly options.
At the time that I built this, Neuro-sama appeared to be using Microsoft Azure TTS, which allows the user to impart some VTuber-standard cuteness into selected voices by controlling pitch and speech rate. I wrote a script that allowed me to quickly demo a variety of voices before settling on the following configuration:
{
"Shiro": {
"azure_speech": {
"name": "en-US-JaneNeural",
"pitch": "10%",
"range": "medium",
"rate": "1.3"
}
},
"Kuro": {
"azure_speech": {
"name": "en-US-SaraNeural",
"pitch": "15%",
"range": "medium",
"rate": "1"
}
}
}Shiro talks quickly because she’s anxious, and Kuro pitches her voice up because she’s the bratty younger sister. The audio quality and expressivity doesn’t begin to compare to ElevenLabs, but the cost is at least negligible.

Avatars
VTubers are most commonly rendered in Live2D, a 2.5D animation technique where flat drawings are layered and warped in order to create the illusion of depth. This technique is simpler for 2D artists to work with than learning full 3D animation, so it’s easier to commission a Live2D avatar than to find a 3D artist to create and rig a 3D avatar, there being overall fewer 3D than 2D artists. Neuro-sama uses a Live2D avatar.
Apart from being easier to commission, I consider 3D avatars strictly superior to Live2D avatars:
- 3D avatars can be viewed from a greater variety of angles, and thus be given more diverse animations.
- 3D avatars have greater platform interoperability: you can use the same 3D avatar for streaming and VR applications, while Live2D avatars are confined to programs that support that specific style of rigging and only allow you to view the avatar from the front.
When I brought the topic up with VTuber-loving friends, I heard multiple claims that Live2D avatars just look better than 3D ones. There’s a specific “Live2D look” with soft, painterly rendering and slow “bouncy” animation that’s become synonymous with VTubers. But this style can be replicated in 3D, given a modeler willing to hand-paint textures and rig animations to match the desired style.

But once again, I’m trying to build out a whole pipeline, and I can’t let things like “quality” slow me down!
VRoid Studio is a free software that allows you to easily make rigged anime-style avatars. The preset options are cute and easy to customizable within the UI, and the models can be exported in the VRM format. The wide adoption of VRM format makes it easy to work with in Unity, which seemed to offer more customization options than any free VTubing-specific software.
I spent like five minutes building an avatar from the presets, then just swapped the hair color to make the sister. They’re twins, after all.

They could benefit from more effort in the texturing and shading, but they’re basically fine for demo purposes. One of the nice things about using the same basic model for both sisters is that I could recycle animations between models.
Animation
Since my models are exportable in VRM format and come with pre-defined animations for different mouth shapes (courtesy of VRoid studio. Man, what a great app!), I could use this Unity asset in order to extract phonemes from audio and play the appropriate animation in real-time.
I now needed an idle animation to ensure that my VTubers didn’t spend the whole stream T-posing. I followed a tutorial to download and apply some free animations from Abobe’s Mixamo platform. It turns out that the kind of animations that seem reasonable as resting poses when previewed on the Mixamo website look lifeless when a figure is cropped and shot in a standard chest-up head-on VTubing pose, which is probably why human VTubers are always bouncing and wiggling. I picked a pair of sufficiently-wiggly animations and tweaked the timing to express the personality of each character, speeding it up for Kuro and slowing it down for Shiro.
Talking to Twitch
Twitch provides an IRC interface for bots to read and send messages in stream chats. I added a module to collect comments as they came in and periodically prompted the LLM to generate a response to the last N comments (unless ignore_audience was set, such as in the case where there are no comments in the chat, or else the generated commentary would endlessly lament the emptiness of the chat):
if not ignore_audience:
commentary = f"Speaker responds to the recent stream comments, unless" \
f"comments are offensive or incomprehensible. In that case, " \
"she instead says something cute but subtly unnerving.\n\n"
else:
commentary = f"Speaker ignores the chat and instead says something cute but subtly unnerving.\n\n"
Putting it all together
I was handling avatar animation in Unity, but wanted to keep as much of the program logic in Python as possible, since every moment spent working with Unity subjected me to horrors. For example: since we’re only going to be looking at our girls from the front, it makes sense to set the camera to “Orthographic”, in order to minimize distortions to the models from rendering perspective. For some reason this caused part of the dress texture to glitch in a distracting way which went away when I set the camera to “Perspective” and did some fiddly things with camera distance and cropping to approximate an orthographic view.
So: Unity would be responsible for displaying character animations and generated assets (voice clips, the image of the chessboard), while Python would be responsible for all the logic requires to generate those assets. Originally I even had Python generate the chessboard in a separate window and then composited the VTubers and chessboard together in the streaming app by setting the VTuber background to a flat greenscreen, but it turned out to be easier to just send Unity a png image of the board and then use it as a texture for a flat panel object rendered behind the VTubers.
I needed some way to allow my Python scripts to talk to my Unity session. The usual way to connect things like this is through gRPC. Unity, being Unity, makes this option nontrivial to implement, and after a week fighting with it I gave up and decided to do everything via HTTP requests instead.
The current setup: I start up an HTTP server in Python. I hit “play” on my Unity project, then hit the “p” key once I’m ready to kick off the stream proper. The Unity process starts making GET requests to the Python server to either update the board state, generate move or chat commentary, or fetch the audio generated from a move or chat commentary request. If I want to pause the process, I hit “p” again and Unity stops playing audio/animations and stops making requests.

Streaming
Since I was going to be streaming to Twitch, I decided to use Twitch Studio to broadcast my stream. I went to go grab a screenshot but the application won’t open and it turns out that they’ve discontinued support for Mac. It was nice while it lasted!
I used BlackHole to create a virtual microphone and then set it as my system default, since Unity does not actually allow you to play audio to arbitrary microphones (on account of Unity’s general evil and badness). This immediately caused mic issues that went remarked-upon in stream but look, I’m just one guy, ok? I don’t want to spend time figuring out what’s happening with the audio, because it’s probably some horrible OS-level thing that will require many engineer-hours to disentangle. Maybe some Foxconn employee fell onto the conveyor belt as they were working on my laptop’s microphone and their dying curse is that audio will break as soon as I try to do something even moderately ambitious, because the point of the curse isn’t really to break the audio, but break my spirit once I realize that any attempt that I make to bring glory to my name will inevitably end in frustration. Just like their spirit was broken by inhuman factory labor conditions. And their spine, after they fell onto the conveyer belt.

Why it fell apart
You know how if you make something cool people will find out about it and reward you in proportion to the effort that you put in?
It turns out that you have to put in some effort to make this happen. After I got my pipeline working, I DMed @yacineMTB on Twitter to ask for advice. He made the reasonable suggestion of sharing clips from streams on 4chan’s worksafe gif board. Another friend of mine suggested promoting the stream on r/AnarchyChess, a subreddit dedicated to chess memes. I didn’t do this, because it turns out that the energy needed to spend hours writing code is not fungible for spending hours writing offbeat-yet-broadly-appealing-hooks to convince strangers to check out my channel.
I have a great deal of practice in trying-and-failing to write code. The appearance of an error message in my console no longer feels like a message that I, personally, am not fit to operate a computer. Not so for trying-and-failing to promote my work. Every time I bring up one of my projects and get shot down, it’s an existential threat. Exile from my tribe, rejection by some Jungian Ur-Father in the form of a derisive comment on an anonymous imageboard.
The way to overcome this is to have a dependable source of ego-reassurance independent from whatever it is that you’re currently failing at. A single error message can’t convince me of worthlessness as a programmer because I’m confident in the quality of work that I’ve done elsewhere. But I didn’t have a dependable source of “hype” for my VTuber project.
My friends did try to support me. They dutifully watched my streams and populated chat with interesting comments. They even tried to get my Twitch channel banned by convincing the VTubers to endorse race riots (actually I wish they hadn’t done this but the girls ended up dodging the question nicely. Thank you for the censorship, OpenAI!) Yet none of them are fans of chess or VTubers specifically. They just want to see me win.
What’s needed for the success of a project like this is people who believe in The Mission, not just in Me. What would that look like?
Chess’s mechanics are coldly rational, but the drama is very human. The piece names– Knight, Bishop, Queen– turn every game into a surreal Medieval epic, a gallant cavalier evading capture by bloodthirsty clergy before being failed by an Amazonian regent. This is not a new idea, Wikipedia informs me: “Romantic players consider winning to be secondary to winning with style.[1]” The strategic superiority of other tactics forced chess to evolve away from Romanticism, and the Romantic school’s proponents resisted in anti-Semitic ways that make me feel a little weird approvingly linking that Wikipedia article, but even the advent of fully automated chess engines wasn’t enough to kill the human element. Stockfish exists, but people still care who the human chess grandmasters are. And the participants in Chess.com’s most popular streamed chess games weren’t even grandmasters, but Internet celebrities.
Who better to showcase the passion and intrigue emergent from the the coldly rational mechanics of chess than adorable anime girls emergent from the coldly rational mechanics of computer code, whose moe speaks to humanity’s ability to read an emotional narrative into any sufficiently complex system?

That’s the case for “AI Chess VTubers”, but it isn’t the end of the case for AI VTubers in general. So…
A five-year vision
When I was in Japan, I ate at a couple of maid cafes, visited the Osaka muscle girl bar and noticed many advertisements for “hostess clubs”. The conceit behind these establishments is that you’re paying for proximity to and attention from attractive woman, but what struck me most about the experience was the unexpected social dynamic. Patrons would often attend in groups, and spend just as much, if not more, time interacting with each other as they did with the staff.
“AI influencers” and “digital waifus” seem poised to encourage the parasocial tendencies that leave people investing in one-sided digital relationships at the expense of mutual camaraderie with peers. Every hour spent interacting with another human being is one that could be spent on a platform that promises to artificially emulate friendship, so it’s in in the interests of artificial-friendship-emulation peddlers to discourage the former in order to profit from the latter.
The alternative is a model of interaction with AI entities that facilitates human connection, modeled off of existing entertainment that encourages such. Fans of existing VTubers don’t seek individual attention from the VTuber as much as they bond with other fans over mutual interest: chatting with each other during streams, producing videos highlighting memorable moments, sharing fan art, and congregating on social media to discuss the streamer’s antics. And sure, “chatting with each other during streams” may not involve coherent sentences, but at least spamming “OMEGALUL” is a social activity.
AI VTubers could be specifically designed to encourage viewers to interact with each other. You could create AI VTubers which combine activities amenable to group discussion (book clubs, study groups, language learning) with niche topics that promote affinity through specificity (working through Hegel, solving topology problems, practicing Toki Pona). Given persistent memory (which I did not implement for my VTubers, even after criticizing Neuro-sama for lacking it), the AI VTuber could learn more about its viewers over time, and encourage the group to notice the merits of each member.
A human VTuber wouldn’t be willing to sink hours into broadcasting to an audience that would never number above the dozens, nor would they be able to memorize facts about each audience member. But with the right infrastructure, the cost of spinning up a new AI VTuber to do so would be negligible.
Obviously, attempting such a thing on a single Macbook wouldn’t work. You’d probably want your own streaming platform that hosts only your own AI VTubers, which means tackling not only parallel AI inference but the challenges of operating and promoting a new social media website. Still… it’s a beautiful dream, right?

Conclusions
Usually I publish my code for every blogpost, but the code for this is awkwardly patched together for my own local setup. I don’t want to be responsible for answering questions about how someone could get this running on their own machine, and I definitely don’t want anyone to see what I’ve done to Unity in the process of getting this working.
If you want to try something like this on your own, I recommend starting with this open-source repository. You can also look at this repository if you just want to make an interactive chatbot with a cute anime avatar.
